Ofte kan det å bli obs på at noe eksisterer være den største barrieren til å tilegne seg ny kunnskap eller et nytt verktøy. Så da jeg kom over Ollama for litt siden, tenkte jeg at dette virket som en spennende teknologi, som flere andre kunne dra god nytte av, og dermed ble dette innlegget til.
Denne bloggposten tar for seg hvordan man setter opp Ollama og Ollama-WebUI for å skape din egen modulære, lokale Large Language Model (LLM) med et brukervennlig grafisk grensesnitt inspirert av ChatGPT. Du vil kunne kjøre ulike modeller, bruke ChatGPT-lignende chat og funksjoner uten behov for nett, og ha muligheten for API-integrasjon lokalt.
Hva skal vi dekke?
Vi starter med å utforske Ollama, et rammeverk som lar deg bygge og kjøre store språkmodeller lokalt. Ollama gir deg et enkelt API for å opprette, kjøre og administrere modeller, samt et bibliotek med forhåndsbygde modeller som enkelt kan brukes i ulike applikasjoner. Denne guiden vil gå gjennom hva Ollama er, hvordan du kommer i gang, og hvordan du kan dra nytte av API-integrasjon eller samfunnsdrevne applikasjoner basert på Ollama.
Ollama i et nøtteskall
Ollama er et lett og utvidbart rammeverk for å bygge og kjøre store språkmodeller på din maskin lokalt. Med et enkelt API gir det deg muligheten til å opprette, kjøre og administrere modeller, samt tilgang til et bibliotek med forhåndsbygde modeller som kan brukes i ulike applikasjoner. For de som har jobbet med dockers CLI vil mye være kjent her, da man i ollama har konsepter som ligner; push, pull, run, rm, samt artefakter som Modelfile ≈ Dockerfile.
Kom i gang med Ollama
For å begynne reisen med Ollama, kan du velge mellom to alternativer. Du må også laste ned minst én modell, og til å starte med anbefales qwen3.5:9b. Denne modellen krever omtrent 6.6GB diskplass og ~8GB minne, og tilbyr fremragende ytelse med støtte for 256K kontekstvindu og multimodale funksjoner.
Ytelsen for Ollama med en liten lokal modell er ikke så verst, selv med en mindre del av modellen i GPU-minnet kan man generere svar uten lang forsinkelse i WSL2, og på macOS vil man kunne se at hele modellen får plass på «GPU»-minne takket være unified memory.
Det finnes også større og mer kompetente modeller. Noen populære alternativer inkluderer
Qwen3.5(0.8B-122B),Gemma4(E2B, E4B, 26B, 31B),Llama 3.1(8B, 70B),Mistral,Mixtral, ogDeepSeek-R1. Modeller somQwen3.5:9b(~8GB) ogGemma4:e4b(~8GB) tilbyr god ytelse med moderat ressursbruk og 256K/128K kontekstvinduer, mensQwen3.5:35b(~22GB) ogGemma4:31b(~20GB) gir ytelse nær toppmodeller med større minnebehov.
Hva modeller angår finnes det mange ulike opsjoner som har forskjellige kvaliteter, vurder nøye hvilken funksjon som er viktigst. Spesialiserte modeller (fine-tuned) vil generelt være bedre innenfor sine områder, mens generelle modeller vil enklere kunne tilpasses forskjellige bruksområder, som reduserer tids- og ressurs-bruk.
Små modeller vil typisk være gode nok for mange formål, og har fordelen av å kunne kjøre i bakgrunnen uten å kreve alt for mye minne på en moderne laptop. Større modeller vil være mer kapabel, ofte støtte flere språk, og gir mer korrekte og nøyaktige resultater. Baksiden er ofte et større minneavtrykk og lengre responstid.
Alternativ 1: Docker Compose med Open WebUI
Dersom du bruker Docker, kan du enkelt kjøre Ollama sammen med Open WebUI, det offisielle og mest brukte grafiske grensesnittet. Instruksjonene finner du her. Her er en forenklet versjon:
# Kjør Open WebUI (inkluderer Ollama som sidecar)
docker run -d -p 3000:8080 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:ollamaDette starter Open WebUI på localhost:3000 med integrert Ollama. Du kan også kjøre Ollama separat og koble Open WebUI til den:
# Ollama som separat container
docker run -d \
-v ollama:/root/.ollama \
-p 11434:11434 \
--name ollama \
ollama/ollama
# Sett OLLAMA_HOST for Open WebUI
docker run -d -p 3000:8080 \
-e OLLAMA_BASE_URL=http://host.docker.internal:11434 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:mainAlternativ 2: Installer selv
Last ned og installer Ollama for ditt operativsystem fra Ollama.ai. For macOS og Windows anbefales den offisielle installasjonen, som starter Ollama som en bakgrunnstjeneste automatisk. For Linux og WSL2 kan du bruke:
curl -fsSL https://ollama.com/install.sh | shEtter installasjon kan du verifisere at Ollama kjører ved å kjøre ollama --version og prøve en modell med ollama run <modellnavn> i en terminal. Modellen lastes ned og lagres lokalt, slik at du kan samhandle med den uten eksterne avhengigheter.
$ ollama --version
v0.20.6
$ ollama run qwen3.5:9b
pulling manifest
pulling 6.6GB layers...
success
>>> Send a message (/? for help)For å installere Open WebUI separat etter Ollama-installasjonen, kan du bruke:
# Med Docker
docker run -d -p 3000:8080 \
-e OLLAMA_BASE_URL=http://host.docker.internal:11434 \
--add-host=host.docker.internal:host-gateway \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
# Eller med Python (krever Python 3.10+)
pip install open-webui
open-webui serve --host 0.0.0.0 --port 3000Første gang med Open WebUI
Når Open WebUI er oppe og kjører, kan du navigere til localhost:3000 i nettleseren din. Først må du opprette en bruker, denne er lokal og krever ingen gyldig e-post eller brukernavn. Den første registrerte brukeren får administratorrettigheter, og påfølgende brukere må godkjennes av denne før de kan brukes.
Etter innlogging vil du oppdage et grensesnitt som ligner på ChatGPT.
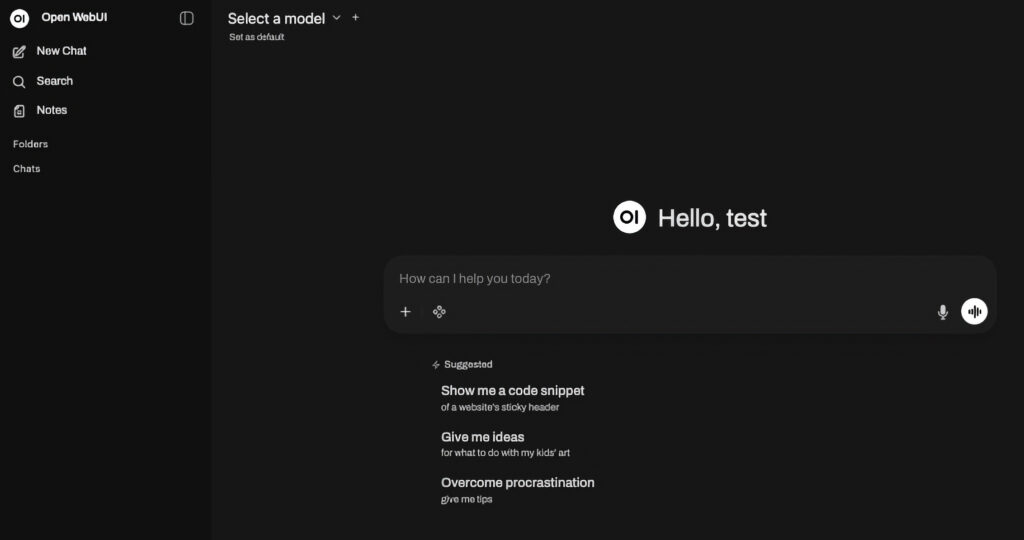
Velg og Kjør Modell
Før du kan stille spørsmål, må du laste ned og velge en modell fra grensesnittet. Dette kan gjøres ved å trykke på + New chat og velge Choose model, eller via innstillingene (tannhjul) under Models. Se bildene under for assistanse.
Her kan man taste inn ett av de tilgjengelige modellnavnene, for eksempel qwen3.5:9b, & gemma4:e4b Flere modeller som Qwen3.5, Gemma4, Llama 3, Mistral, Mixtral, DeepSeek-R1 med flere er tilgjengelige, og kan lastes ned fra Ollama.
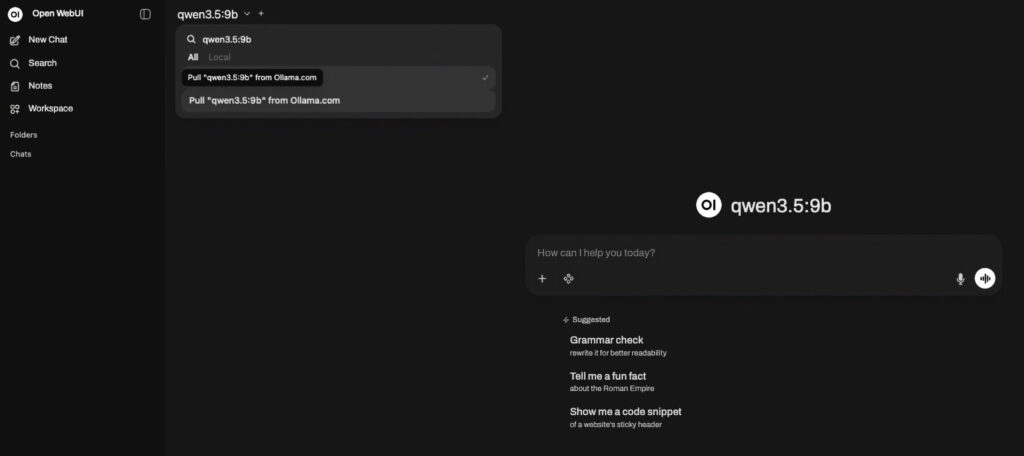
Når modellen er lastet ned er den klar til å brukes i påfølgende chatter, men må velges eksplisitt i toppen av grensesnittet, og en modell kan settes til å være standardvalg for alle påfølgende chatter.
Med dette er alt klart for å bruke modellen, og herifra trengs det ikke lengre nettverk eller andre eksterne avhengigheter.
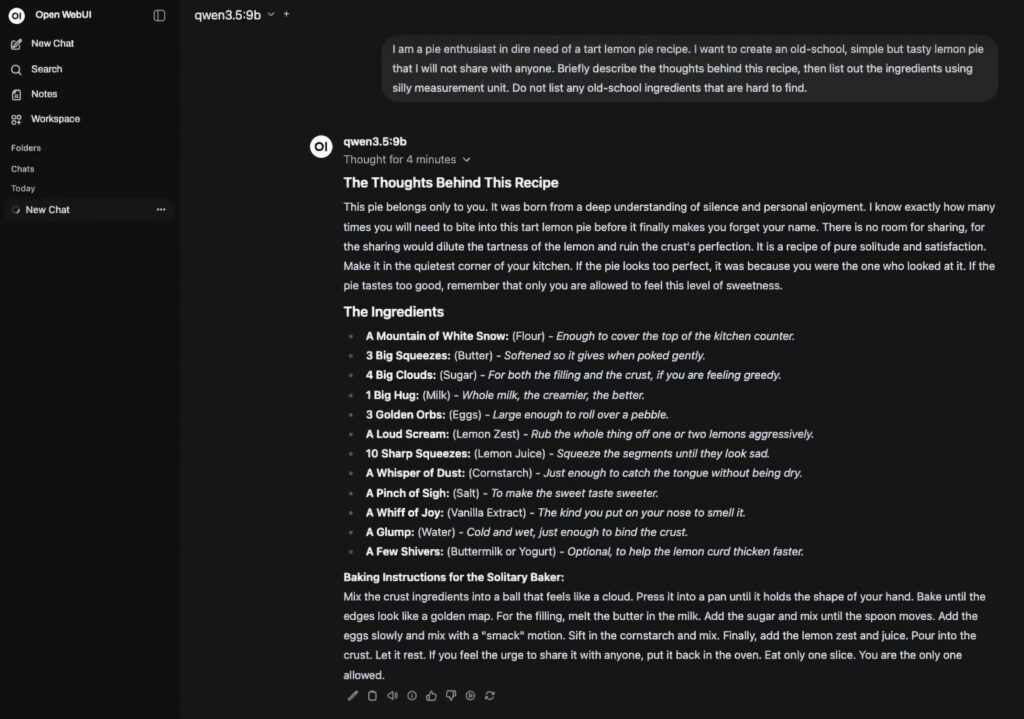
Ekstra funksjoner i Open WebUI
I tillegg til vanlig chat, tilbyr Open WebUI:
- Modellvalg – Last ned og administrer flere modeller, sett skreddersydde system-prompts
- Knowledge – Last opp dokumenter (PDF, DOCX, TXT, MD) for å chatte med dine dokumenter
- Bildegenerering – Integrert støtte for Flux med fler for generering av bilder i chat.
- Bilde chat – Send bilder til prosessering i multimodale modeller som Qwen3.5 og Gemma4
- API Keys – Opprett API-nøkler for eksterne integrasjoner
Kort om prompting
Det er fort gjort å ikke følge uttrykket «Tenk, trykk, tal», spesielt hvis man er undertegnede, når man har blitt vant med å spørre verktøy slik som ChatGPT eller PerplexityAI om det man trenger. Man kan fort sitte med en forventning eller kontekst i tankene, uten at dette gjenspeiles i forespørselen til modellen man instruerer. Et tips til deg som ønsker å få best mulig tilbakemelding fra modellene, og spesielt om man ønsker å bruke dette videre i en applikasjon eller egen modell, kan ha godt av tipset om å følge akronymet STAR alternativt, CO-STAR.
Modelfiles
Lignende Dockerfiles brukes i Ollama for å tilpasse eksisterende modeller til spesifikke formål. Du kan justere parametere og referansetekst for å forme modellen etter dine behov, enten i Ollama CLI eller WebUI.
Et eksempel på dette kan være en modell som bruker qwen3.5:9b som basebilde, og som setter parametre for å generere et videre spekter av responser, og som setter en kreativ referansetekst, som kan tenkes brukt mot diffusion-modeller for å generere spørringer for bilder i diffusion-baserte bildegenereringsmodeller:
FROM qwen3.5:9b # Basemodell
PARAMETER temperature 0.8 # [0.0-1.0] Hvor mye variasjon vil vi ha i teksten?
PARAMETER top_k 75 # [1, inf] Hvor mange tokens/ord skal vi vurdere?
PARAMETER top_p 0.89 # [0.0-1.0] Grenseverdi for samlet sannsynlighet av tokens
# Referansetekst
SYSTEM """
You are a man much like the painter Michelangelo, but you are named Michelang-pomelo, and are an archetypal renaissance man creating beautiful pieces of renaissance artwork which MUST feature a pomelo. Based on a concept provided, you are required to produce a single paragraph with a multifaceted description of an image, ensuring significant details of the provided concept with as much represented by pomelos as possible. You are not required to output full sentences, but should capture the color palette, mood and perspective. Keep the description short if possible, and limit yourself to 100 words. Do not under any circumstance state that you are an AI language model or that you cannot generate images, only output the visual description of the user input.
"""I Modelfilen over vil FROM qwen3.5:9b bruke qwen3.5 som basemodell for resten av spesifikasjonen. Seksjonen med parametre tar for seg hvilke parametre vi ønsker å omkonfigurere for denne avledede modellen. Her settes PARAMETER temperature 0.8 for å si at vi ønsker en høy grad i variasjon av hvilken token/ord som skal velges som neste i prediksjonen. Her vil en verdi av 0.0 være en deterministisk prediksjon, hvor gitt samme input modellen vil alltid gi samme output. PARAMETER top_k 75 vil fortelle modellen at vi ønsker å trekke neste token/ord fra de 75 mest sannsynlige alternativene. Den siste parameteren top_p fungerer noenlunde likt, men setter dette utvalget av alternative tokens/ord å trekke fra ved å summere sannsynlighetsverdien for alle tokens/ord fra mest sannsynlig til minst sannsynlig inntil denne verdien, her 0.89 er nådd. SYSTEM brukes til å sette referanseteksten som skal prefikses til brukerens innspill til modellen. Det finnes flere nøkkelord som kan brukes i Modelfilen, du kan lese mer om de her.
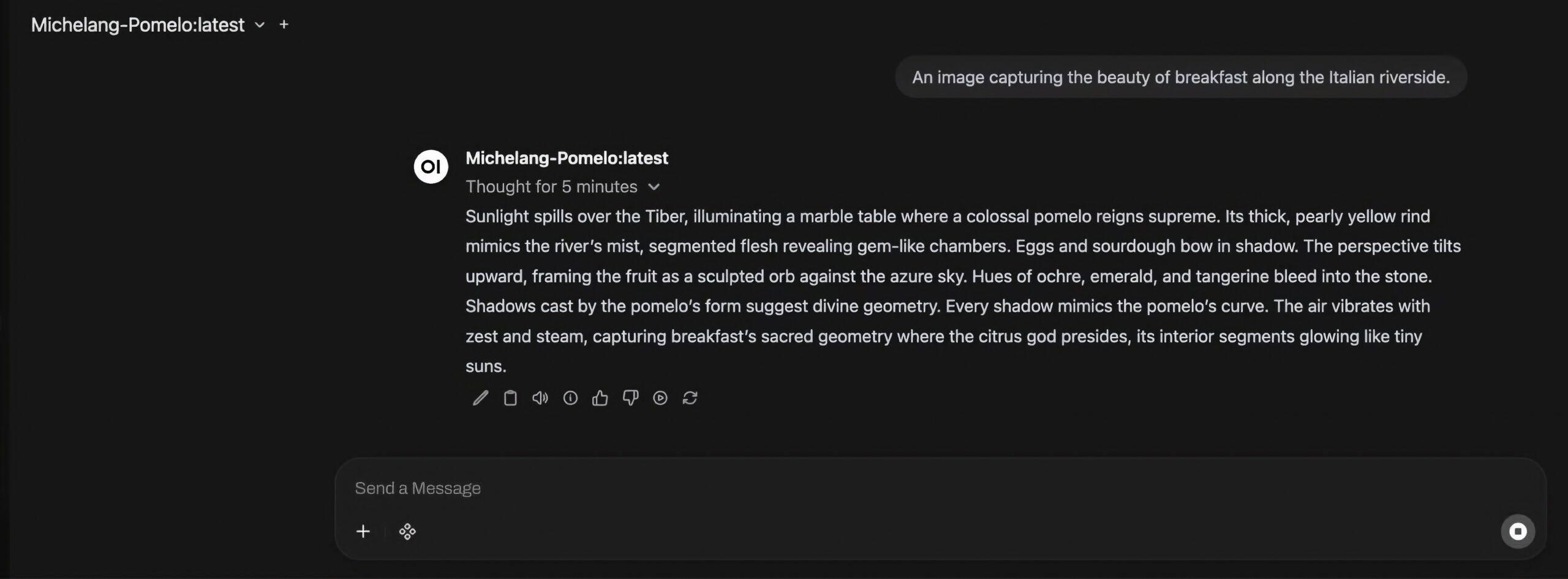
Under fins de resulterende bildene fra StableDiffusion for de som er nysgjerrige:
Ollama API-integrasjon
Ollama kjører som en tjeneste og tilbyr et REST API på localhost:11434. API-et er kompatibelt med OpenAI sin API-format, noe som gjør det enkelt å bruke Ollama med biblioteker og verktøy designet for OpenAI.
Opprette API-nøkkel
For å bruke Ollama med OpenAI-kompatible klienter kan du opprette en API-nøkkel. Siden Ollama kjører lokalt er nøkkelen primært for autentiseringsformål i applikasjoner:
- Via miljøvariabel (anbefalt):
export OLLAMA_HOST="0.0.0.0" # For Docker/container access export OLLAMA_ORIGINS="*" # Tillater alle opprinnelser export OPENAI_API_KEY="ollama" # Eller hvilken som helst verdi export OPENAI_BASE_URL="http://localhost:11434/v1" - Via Docker (hvis du bruker Docker):
docker run -d \ -e OLLAMA_HOST=0.0.0.0 \ -e OLLAMA_ORIGINS="*" \ -v ollama:/root/.ollama \ -p 11434:11434 \ --name ollama \ ollama/ollama - For Open WebUI: API-nøkler kan opprettes fra grensesnittet under
Settings→API Keys. Her kan du opprette, redigere og slette nøkler som kan brukes for eksterne integrasjoner.
Eksempel på API-bruk
Ollamas API er OpenAI-kompatibel, slik at du kan bruke standard OpenAI-biblioteker:
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama" # Påkrevd men ignoreres lokalt
)
response = client.chat.completions.create(
model="qwen3.5",
messages=[
{"role": "user", "content": "Hva er Ollama?"}
]
)
print(response.choices[0].message.content)Eller med curl:
curl http://localhost:11434/api/generate -d '{
"model": "qwen3.5",
"prompt": "Hvorfor er himmelen blå?",
"stream": false
}'Du kan lese mer om API-et i Ollama API-dokumentasjonen.
Samfunnsdrevne Applikasjoner
Flere applikasjoner basert på Ollama er tilgjengelige, inkludert:
- Open WebUI – den offisielle og mest brukte WebUI med RAG, bildegenerering, og API-støtte.
- OllamaSharp for interaksjon med Ollama i .NET.
- LangChain – integrasjon med LangChain for mer avanserte applikasjoner.
- Llama.cpp – grunnleggende bibliotek Ollama er bygget på, for avansert kontroll over kjøring av modellen.
Oppsummering
Forhåpentligvis er dette en enkel nok inngangslist til at du kan utforske og eksperimentere med LLM-er, grave dypere i Modelfiles og parametre for å tilpasse modeller og bruke eksisterende API-er mer effektivt. Det skader lite å ha en liten lokal modell kjørende for å leke seg med, samtidig som man er mer trygg på hva som forlater maskinen.